The 2015-2016 NBA season is dawning upon us, and as usual, ESPN has been doing their usual #NBArank, where they are ranking players based on the following non-rigorous methodology:
We asked, “Which player will be better in 2015-16?” To decide, voters had to consider both the quality and quantity of each player’s contributions to his team’s ability to win games. More than 100 voters weighed in on nearly 30,000 pairs of players.
Of course, while I suspect this type of thing has to be just for fun , it has generated a great deal of controversy with many arguments ensuing between fans. For example, Kobe Bryant being ranked 93rd overall in the NBA this year gained a fair deal of criticism from Stephen A. Smith on ESPN First Take.
In general, at least to me, it does not make any sense to rank players from different positions that bring different strengths to a team sport such as basketball. That is, what does it really mean for Tim Duncan to be better than Russell Westbrook (or vice-versa), or Kevin Love to be better than Mike Conley (or vice-versa), etc…
From a mathematical/data science perspective, the only sensible thing to do is to take all the players in the league, and apply a clustering algorithm such as K-means clustering to group players of similar talents and contributions into groups. This is not a trivial thing to do, but it is the sort of thing that data scientists do all the time! For this analysis, I went to Basketball-Reference.com, and pulled out last season’s (2014-2015) per game averages of every player in the league, looking at 25 statistical factors from FGA, FG% to STL, BLK, and TOV. One can see that this is a 25-dimensional problem.
Our goal then is to consider the problem where denoting 

where 

The first thing to do is to decide how many clusters we want to use in our solution. This is done by looking at the within sum of squares (WSS) plot:

First, we will use 3 clusters in our K-means solution. In this case, the between sum of squares versus total sum of squares ratio was 77.0%, indicating a good “fit”). We use three clusters to begin with, because based on visual inspection, the data clusters very nicely into 3 clusters. The plots obtained were as follows:
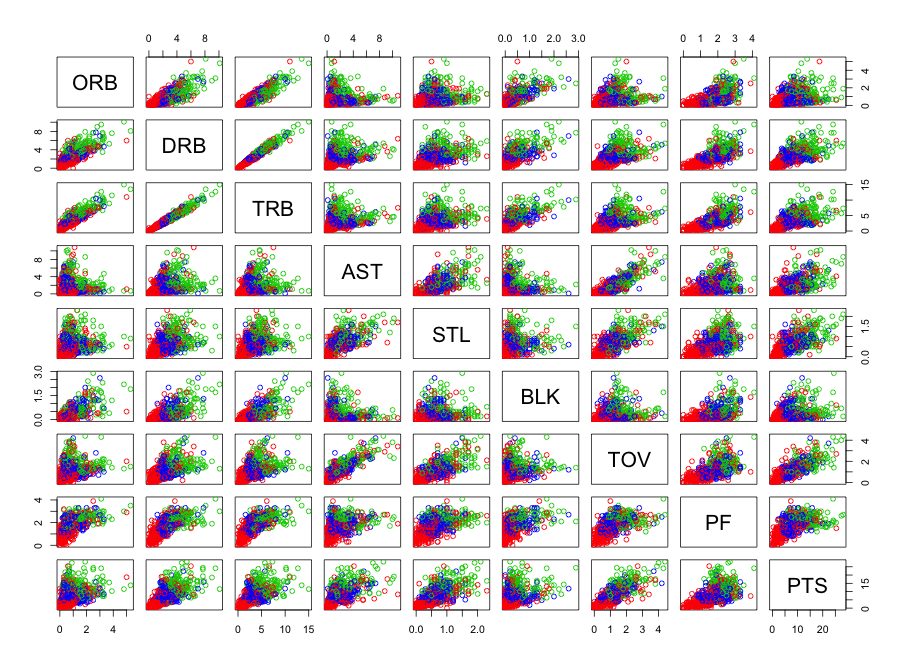

The three clusters of players can be found in the following PDF File. Note that the blue circles represent Cluster 1, the red circles represent Cluster 2, and the green circles represent Cluster 3.
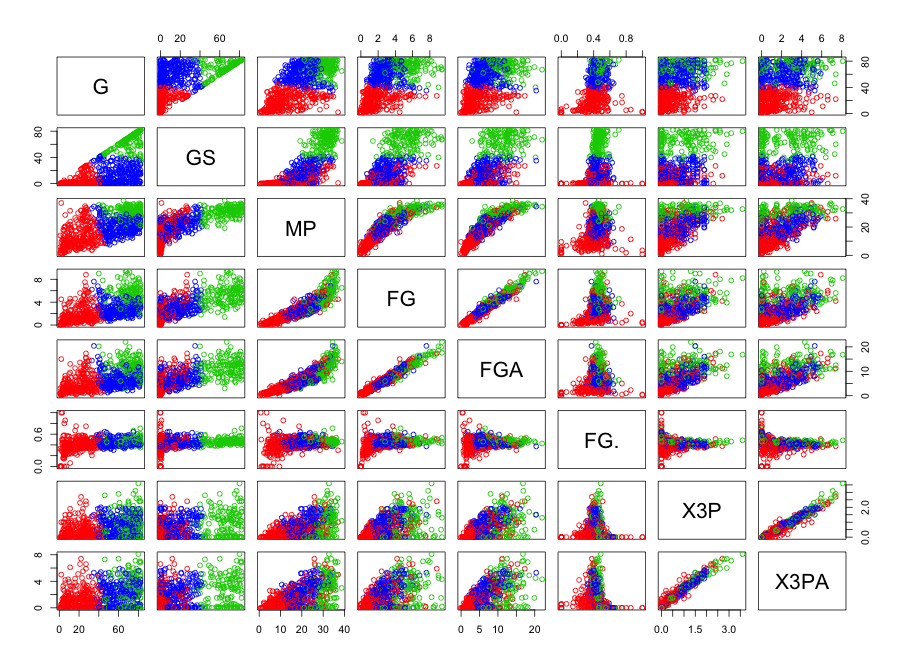
Next, we dramatically increase the number of clusters to 20 in our K-means solution.
Performing the K-means clustering, we obtain the following sets of scatter plots. (Note that, it is a bit difficult to display a 25×25 plot on here, so I have split them into a series of plots. Note also, that the between sum of squares versus total sum of squares ratio was 94.8 %, indicating a good “fit”):
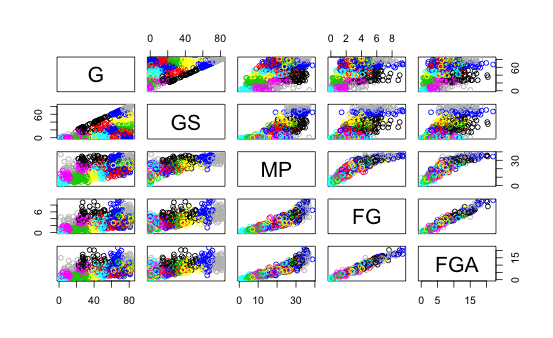



The cluster behaviour can be seen more clearly in three dimensions. We now display some examples:


The 20 groups of players we obtained can be seen in the PDF file linked below:
The legend for the clusters obtained was:

Two sample group clusters from our analysis are displayed below in the table. It is interesting that the analysis/algorithm provided that Carmelo Anthony and Kobe Bryant belong in one group/cluster while LaMarcus Aldridge, Lebron James, and Dwyane Wade belong in another cluster.
| Group 16 | Group 19 |
| Arron.Afflalo.1 | Steven.Adams |
| Carmelo.Anthony | LaMarcus.Aldridge |
| Patrick.Beverley | Bradley.Beal |
| Chris.Bosh | Andrew.Bogut |
| Kobe.Bryant | Jimmy.Butler |
| Jose.Calderon | DeMarre.Carroll |
| Michael.Carter.Williams.1 | Michael.Carter.Williams |
| Darren.Collison | Mike.Conley |
| Goran.Dragic.1 | DeMarcus.Cousins |
| Langston.Galloway | Anthony.Davis |
| Kevin.Garnett | DeMar.DeRozan |
| Kevin.Garnett.1 | Mike.Dunleavy |
| Jeff.Green.2 | Rudy.Gay |
| George.Hill | Eric.Gordon |
| Jrue.Holiday | Blake.Griffin |
| Dwight.Howard | Tobias.Harris |
| Brandon.Jennings | Nene.Hilario |
| Enes.Kanter.1 | Jordan.Hill |
| Michael.Kidd.Gilchrist | Serge.Ibaka |
| Brandon.Knight.1 | LeBron.James |
| Kevin.Martin | Al.Jefferson |
| Timofey.Mozgov.2 | Wesley.Johnson |
| Rajon.Rondo.2 | Brandon.Knight |
| Derrick.Rose | Kawhi.Leonard |
| J.R..Smith.2 | Robin.Lopez |
| Jared.Sullinger | Kyle.Lowry |
| Thaddeus.Young.1 | Wesley.Matthews |
| Luc.Mbah.a.Moute | |
| Khris.Middleton | |
| Greg.Monroe | |
| Donatas.Motiejunas | |
| Joakim.Noah | |
| Victor.Oladipo | |
| Tony.Parker | |
| Chandler.Parsons | |
| Zach.Randolph | |
| Andre.Roberson | |
| Rajon.Rondo | |
| P.J..Tucker | |
| Dwyane.Wade | |
| Kemba.Walker | |
| David.West | |
| Russell.Westbrook | |
| Deron.Williams |
If we use more clusters, players will obviously be placed into smaller groups. The following clustering results can be seen in the linked PDF files.
- 50 Clusters – (between_SS / total_SS = 97.4 %) – PDF File
- 70 Clusters – (between_SS / total_SS = 97.8 %) – PDF File
- 100 Clusters – (between_SS / total_SS = 98.3 %) – PDF File
- 200 Clusters (extreme case) – (between_SS / total_SS = 99.1 %) – PDF File
I did not include the visualizations for these computations because they are quite difficult to visualize.
Looking at the 100 Clusters file, we see two interesting results:
- In Cluster 16, we have: Carmelo Anthony, Chris Bosh, Kobe Bryant and Kevin Martin
- In Cluster 74, we have: LaMarcus Aldridge, Anthony Davis, Rudy Gay, Blake Griffin, LeBron James and Russell Westbrook
CONCLUSIONS:
We therefore see that is does not make much mathematical/statistical sense to compare and two pairs of players. In my opinion, the only logical thing to do when ranking players is to decide on rankings within clusters. So, based on the above analysis, it makes sense to ask for example whether Carmelo is a better player than Kobe or whether Lebron is a better player than Westbrook, etc… But, based on last season’s statistics, it doesn’t make much sense to ask whether Kobe is a better player than Westbrook, because they have been clustered differently. I think ESPN could benefit tremendously by using a rigorous approach to these sorts of things which spark many conversations because many people take them seriously.

One reply on “Ranking NBA Players”
Best of the best!